Ein KI-Agent ist ein Softwaresystem, das eine Aufgabe eigenständig über mehrere Schritte löst: Es plant das Vorgehen, ruft Werkzeuge wie Datenbanken, Software oder APIs auf, wertet die Zwischenergebnisse aus und entscheidet daraufhin eigenmächtig den nächsten Schritt. Anders als ein KI-Chatbot, der auf eine Eingabe eine Antwort gibt, handelt ein Agent selbstständig, bis er sein Ziel erreicht hat.
KI-Agenten bearbeiten Aufgaben, deren Lösungsweg nicht vorab feststeht. Etwa eine Wettbewerbsrecherche, eine Anomalieprüfung in Maschinendaten oder eine Anfrage über mehrere Systeme hinweg.
Das heute Verständnis hat sich seit etwa 2023 etabliert, als Large Language Models (LLMs) als steuernde Komponente in solche Systeme einzogen.
Das theoretische Fundament geht zurück auf Russell & Norvig (1995): Ein Agent ist demnach eine Einheit, die ihre Umgebung wahrnimmt und auf sie einwirkt.
In den Geschäftsprozessen kommt ein Agent dort zum Einsatz, wo eine Aufgabe mehrere Schritte mit Entscheidungen dazwischen erfordert und der Pfad nicht deterministisch ist.
Ein häufiges Missverständnis betrifft den Begriff Agentic AI: Das ist keine Synonym-Variante von KI-Agent, sondern bezeichnet die Eigenschaft autonomen, zielgerichteten Handelns. Der KI-Agent ist das Artefakt, Agentic AI die Eigenschaft, die es realisiert. Auch das LLM ist nicht der Agent, sondern dessen kognitiver Kern. Dieser ist beliebig austauschbar.
Inflationär wird der Begriff derzeit vor allem in der Produkt- und Marketingkommunikation verwendet. Gartner nennt das Phänomen „Agent-Washing“: die Umbenennung bestehender Chatbots, RPA-Bots und Assistenten ohne tatsächliche agentische Fähigkeiten.
Woran man einen echten KI-Agenten erkennt
Der belastbarste Trennstrich gegen Agent-Washing ist ein Vier-Schritt-Kriterium:
- Ein echter Agent plant den nächsten Schritt,
- führt ihn über ein Tool aus,
- beobachtet das Ergebnis
- und steuert bei Bedarf auf Basis der Beobachtung nach.
Fehlt einer dieser Schritte, handelt es sich meist um einen Chatbot mit API-Anbindung oder einen vorab verdrahteten Workflow (Automatisierung).
Die Größenordnung zeigt die Anbieterlandschaft: Gartner identifizierte rund 130 Anbieter, die sich als Agentic-AI-Lösung positionieren. Die meisten dieser Angebote hält Gartner aber für umetikettierte Assistenten oder Chatbots ohne mehrschrittige Autonomie.
Wer sichergehen möchte, dass es sich um einen echten KI-Agenten handelt, kann sich an diesen drei sichtbaren Indikatoren orientieren:
- Dynamische Tool-Auswahl: Das System entscheidet zur Laufzeit, welches Werkzeug oder welche Datenquelle es aufruft. Es existiert kein vorab konfigurierter Pfad. Wenn jeder Schritt im Flow-Editor sichtbar ist, ist es ein Workflow.
- Zwischenbeobachtung beeinflusst den nächsten Schritt: Bei demselben Input mit unterschiedlichen Zwischenergebnissen führt das System unterschiedliche Folgeschritte aus. Wer das nicht reproduzieren kann, hat keinen Agenten vor sich.
- Persistentes Gedächtnis über Sessions hinweg: Der Agent kann auf frühere Interaktionen oder Zwischenstände zugreifen. Ein zustandsloser Single-Turn-Bot kann das nicht.
Wie baue ich einen KI-Agenten?
Ein Agent entsteht nicht aus einem einzelnen Werkzeug, sondern aus mehreren Schichten, die zusammenarbeiten:
- dem Sprachmodell als kognitivem Kern,
- einem Framework, das den Loop steuert,
- einer Anbindung an die Werkzeuge, mit denen der Agent arbeitet,
- und einer Schicht, die jeden Schritt aufzeichnet.
Wer diese Schichten auseinanderhält, findet sich in der Tool-Landschaft schneller zurecht als anhand der Anbieterlisten.
Die erste Entscheidung betrifft nur eine dieser Schichten, nämlich das Framework (2.): Schreibt man den Agenten selbst in Code, oder baut man ihn auf einer visuellen Oberfläche zusammen (Low/No Code)? An dieser Gabelung trennen sich die beiden Hauptwege.
Selbst coden
Wer den Code-Weg geht, arbeitet mit einem Orchestrierungs-Framework. Dessen Aufgabe ist es, den Agenten-Loop zu steuern. Er koordiniert Planung, Tool-Aufrufe, Zustand und die Wiederaufnahme nach einem Abbruch zu koordinieren.
Welches Framework das richtige ist, hängt vom Schwerpunkt des Projekts ab.
LangGraph gilt 2026 als verbreitetste Wahl für produktive, mehrschrittige Agenten, weil es den Ablauf als Graph mit Zustandspersistenz und Rollback modelliert und damit auch dann zuverlässig bleibt, wenn ein Schritt mitten im Lauf abbricht.
Geht es eher darum, schnell einen rollenbasierten Prototyp aus mehreren Agenten aufzusetzen, ist CrewAI der direktere Weg.
Sucht der Agent überwiegend in großen Wissensbeständen, spielt LlamaIndex seine Stärke aus, weil Retrieval dort im Zentrum steht.
Und wer in einem Python-Team mit strikten Typen arbeitet, der kann auf Pydantic AI zurückgreifen.
Daneben bieten die großen Modellanbieter eigene SDKs an. Etwa das OpenAI Agents SDK, das Claude Agent SDK von Anthropic oder Google ADK. Diese lohnen sich vor allem dann, wenn man ohnehin in einem dieser Ökosysteme zu Hause ist.
Code-Lösungen bieten die maximale Flexiblität, erfordern aber aktuell auch einen hohen technischen Skill.
No-/Low-Code
Mit No-Code bzw. Low-Code Lösungen lassen sich KI-Agenten auf Weboberflächen mit weniger komplexeren Programmierarbeiten abbilden. Welcher Baukasten passt, hängt oft von der Aufgabe selbst ab.
Ist der Agent nur ein Schritt in einer größeren Prozessautomatisierung — er soll etwa eine E-Mail lesen, Daten daraus ziehen, eine Datenbank aktualisieren und am Ende eine Benachrichtigung schicken —, dann ist n8n als Workflow Automation Platform die naheliegende Wahl.
N8n bringt Schleifen und Fehlerbehandlung von Haus aus mit und der Agent fügt sich sauber in den restlichen Ablauf ein.
Flowise und Langflow sind dagegen offene Werkstätten speziell für LLM-Pipelines.
Langflow bindet oben erwähntes LangGraph direkt ein und eignet sich deshalb auch für zustandsbehaftete Loops.
Dify geht einen Schritt weiter und bündelt Builder, Wissensbasis, API-Schicht und Logging in einem einzigen Produkt.
Wer vor allem viele verschiedene Dienste verbinden muss, ist mit Make oder Zapier gut bedient, weil dort die Konnektor-Abdeckung am breitesten ist.
Inzwischen sind auch die großen Anbieter in diesen Bereich eingestiegen, etwa OpenAI mit dem OpenAI Agent Builder.
Zwei Schichten On Top
Zwei weitere Schichten liegen quer zu dieser Entscheidung: Sie kommen hinzu, egal ob man sich für Code oder No-Code entschieden hat.
Die erste ist die Verbindung zwischen Agent und Werkzeug. Damit ein Agent ein Tool überhaupt nutzen kann, braucht er eine standardisierte Anbindung, und genau das leistet das Model Context Protocol (MCP).
Anthropic hat es 2024 vorgestellt und Ende 2025 an die Linux Foundation übergeben; inzwischen unterstützen es alle großen Anbieter, und die führenden Frameworks haben es zum Standard für Tool-Aufrufe gemacht.
MCP regelt dabei die Verbindung vom Agenten zum Werkzeug, während das verwandte A2A-Protokoll (Google, 2025) die Verbindung von Agent zu Agent in Multi-Agent-Systemen übernimmt. In der Praxis heißt das vor allem eines: Bevor man eine eigene Integration schreibt, prüft man, ob es für das gewünschte Tool bereits einen fertigen MCP-Server gibt.
Die zweite Schicht, die in beiden Fällen dazugehört, ist Observability. Also die Beobachtung dessen, was der Agent tatsächlich tut. Sie ist nötig, weil Agenten lautlos scheitern: Eine halluzinierte Antwort kommt ohne Fehlermeldung zurück, und klassisches Monitoring aus Latenz und Fehlerraten bemerkt davon nichts.
Spezialisierte Werkzeuge schließen diese Lücke, indem sie jeden einzelnen Schritt aufzeichnen. Also jeden LLM-Aufruf, jeden Tool-Call, jede Planungsentscheidung.
Welches davon passt, hängt wieder vom Umfeld ab: LangSmith ist eng mit LangChain und LangGraph verzahnt, Langfuse ist die quelloffene und framework-unabhängige Variante, und Arize Phoenix bietet die größte Tiefe bei der Auswertung.
Diese Schicht ist kein nachträglicher Zusatz, sondern die praktische Antwort auf zwei Probleme, die weiter unten im Beitrag auftauchen: auf die Failure-Modes, etwa wenn der Token-Verbrauch in der Testphase nicht mitgemessen wird, und auf die Protokollierungspflicht des EU AI Act, nach der jeder Tool-Call und jeder Planungsschritt nachvollziehbar sein muss.
Wie ein KI-Agent arbeitet
Die Architektur unterscheidet sich grundlegend von einem Chatbot, der einen Prompt entgegennimmt und eine Antwort zurückgibt.
Ein Agent läuft in einer Schleife, in der das LLM nicht der Ausführer ist, sondern der Controller: Es erzeugt strukturierte Anweisungen, die andere Komponenten interpretieren — Datenbankabfragen, API-Calls, Code-Ausführung. Aus dieser Trennung folgt: Agenten müssen anders kalkuliert werden als Chat-Anwendungen. Pro Aufgabe wird das LLM mehrfach aufgerufen, oft dutzendfach.
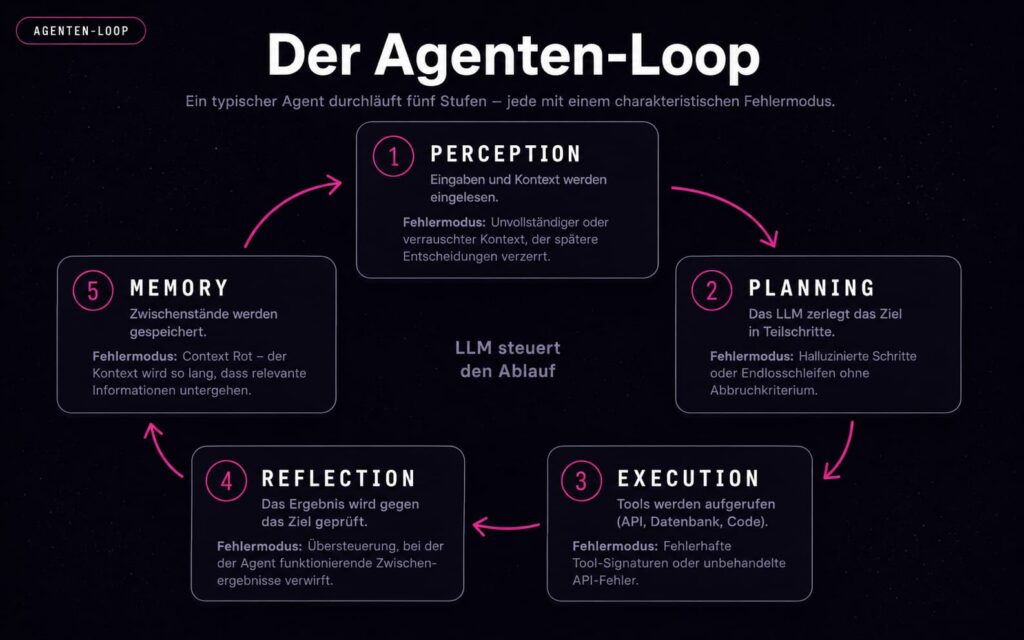
Der Agenten-Loop
Ein typischer Agent durchläuft fünf Stufen, jede mit einem charakteristischen Fehlermodus:
- Perception — Eingaben und Kontext werden eingelesen. Fehlermodus: unvollständiger oder verrauschter Kontext, der spätere Entscheidungen verzerrt.
- Planning — Das LLM zerlegt das Ziel in Teilschritte. Fehlermodus: halluzinierte Schritte oder Endlosschleifen ohne Abbruchkriterium.
- Execution — Tools werden aufgerufen (API, Datenbank, Code). Fehlermodus: fehlerhafte Tool-Signaturen oder unbehandelte API-Fehler.
- Reflection — Das Ergebnis wird gegen das Ziel geprüft. Fehlermodus: Übersteuerung, bei der der Agent funktionierende Zwischenergebnisse verwirft.
- Memory — Zwischenstände werden gespeichert. Fehlermodus: Context Rot — der Kontext wird so lang, dass relevante Informationen untergehen.
Das ReAct-Pattern
Der heutige De-facto-Standard für die Verzahnung von Denken und Handeln ist ReAct (Reasoning + Acting). Shunyu Yao und Mitautoren stellten das Pattern 2022 bei Princeton und Google Research vor.
Der Agent denkt einen Schritt, ruft ein Tool auf, beobachtet das Ergebnis, denkt erneut. Das macht er so lange, bis ein Endzustand erreicht ist.

In den Benchmarks ALFWorld und WebShop übertraf ReAct frühere Imitations- und Reinforcement-Learning-Verfahren um absolut 34 beziehungsweise 10 Prozentpunkte Erfolgsrate, mit nur ein bis zwei In-Context-Beispielen.
ReAct lohnt sich, wenn die Umgebung unsicher oder verrauscht ist. Bei Aufgaben ohne Tools fügt ReAct nur Overhead hinzu. In diesem Fall ist eine reine Chain-of-Thought-Aufforderung leichter.
Bei deterministischen Workflows, in denen jeder Schritt vorab bekannt ist, ist ein Plan-and-Execute-Ansatz günstiger. Er plant einmal und führt dann aus, statt zwischen jeder Aktion neu zu reasonen.
Agententypen und wann man welchen nimmt
Die akademische Taxonomie nach Russell & Norvig unterscheidet vier Grundtypen, sortiert nach steigender Allgemeinheit. Sie eignet sich als Auswahlraster:
- Simple Reflex Agents reagieren ausschließlich auf den aktuellen Input. Bsonders dann geeignet, wenn die Aufgabe zustandslos und der nächste Schritt aus der Eingabe direkt ableitbar ist.
- Model-based Reflex Agents halten einen internen Zustand der Umgebung. Diese sind nötig, sobald frühere Beobachtungen die nächste Entscheidung beeinflussen.
- Goal-based Agents bewerten Aktionen daran, ob sie ein definiertes Ziel näherbringen. Diese sind der Standard für die meisten heutigen LLM-basierten Agenten in Geschäftsprozessen.
- Utility-based Agents wägen zwischen mehreren Zielen mit unterschiedlicher Wichtigkeit ab. Vor allem relevant bei Trade-offs, etwa Kosten gegen Geschwindigkeit gegen Genauigkeit.
Jeder dieser Typen lässt sich als Learning Agent erweitern, der aus Ergebnissen lernt und sein Verhalten anpasst.
Quer dazu liegt die Frage Single-Agent oder Multi-Agent-System (MAS).
Ein einzelner Agent reicht, solange die Aufgabe als zusammenhängende Sequenz lösbar ist. Erst wenn sie in klar trennbare Subaufgaben mit eigenen Fachdomänen zerfällt — etwa Recherche, Analyse, Reporting — wird ein Orchestrator-Agent sinnvoll, der spezialisierte Worker-Agenten koordiniert. MAS kostet ein Vielfaches an Tokens (siehe weiter unten).
Als Heuristik gilt: erst aufteilen, wenn die Subaufgaben unterschiedliche Fachdomänen, Tool-Sets oder Kontextfenster brauchen — nicht, weil ein Single-Agent gelegentlich Fehler macht.
KI-Agent oder Chatbot, RPA, Workflow? Was man wann nimmt
Die Wahl des richtigen Werkzeugs hängt an der Aufgabenstruktur, nicht am verfügbaren Tool-Stack.
- RPA / klassischer Workflow: Der Pfad ist deterministisch und vorab bekannt. Jeder Schritt lässt sich als Regel oder Klickpfad festlegen. Beispiel: Rechnungsdaten aus PDF in SAP übernehmen.
- Chatbot: Eine Frage führt zu einer Antwort. Keine Mehrschritt-Ausführung, keine externen Aktionen. Beispiel: FAQ zum Produktportal beantworten.
- KI-Agent: Die Aufgabe erfordert mehrere Schritte, deren Reihenfolge vom Zwischenergebnis abhängt. Beispiel: Zehn Wettbewerber identifizieren, ihre Preisseiten analysieren, einen Vergleichsreport erstellen. Das ganze wöchentlich, mit wechselnden Wettbewerbern.
- Assistent / Copilot: Reaktiv-unterstützend, ohne autonome Mehrschritt-Ausführung. Der Mensch bleibt im Loop und gibt nach jedem Schritt frei. Gartner ordnet Assistenten explizit unterhalb von Agenten ein.
Wann sich ein KI-Agent lohnt
Die Einsatzschwelle lässt sich an drei Kriterien festmachen:
- Die Aufgabe hat hohe Pfadvielfalt (deterministische Aufgaben gehören in RPA),
- sie ist wiederkehrend (Einmal-Aufgaben rechtfertigen die Entwicklungskosten nicht),
- und sie hat einen klar prüfbaren Outcome (sonst lässt sich nicht messen, ob der Agent funktioniert).
Die Kostengrößenordnungen, die in vielen Glossaren fehlen, sind der zweite Teil der Lohnt-sich-Entscheidung. Agentische Systeme verbrauchen pro Aufgabe 5- bis 30-mal mehr Tokens als eine einzelne Chat-Interaktion:
- Einfache Tool-Calling-Agenten: 5.000–15.000 Tokens pro Aufgabe.
- Komplexe Multi-Agent-Systeme: 200.000 bis über 1.000.000 Tokens pro Aufgabe.
- Unbeschränkter Software-Engineering-Agent: laut einer Untersuchung des Stevens Institute of Technology rund 5–8 USD pro gelöstem Issue. Der Wert gilt für einen Agenten ohne Budget- oder Schritt-Begrenzung; mit gesetzten Limits liegt er tiefer.
- Inferenzkosten auf Unternehmensebene: Laut ICONIQ Capital (State of AI, Januar 2026, Befragung von rund 300 Software-Executives) entfallen bei Scaling-Stage-AI-Unternehmen rund 23 Prozent des Umsatzes auf Inferenz — pro 1 Mio. USD Produktumsatz also etwa 230.000 USD reine Modellkosten.
Eine architektonische Stellschraube für Multi-Agent-Systeme ist die hierarchische Verteilung der Modellklassen: Frontier-Modelle nur für den Orchestrator, Budget-Modelle für die Worker.
In einer Benchmark zur Verarbeitung von Finanzdokumenten (SEC-Filings) wurden so rund 97,7 Prozent der Vollkosten-Genauigkeit bei rund 60,9 Prozent der Kosten erreicht. Ob sich diese Werte auf andere Domänen übertragen lassen, ist nicht belegt. Der Hebel selbst (kleine Modelle für Routine-Subaufgaben) gilt allgemeiner.
Beispielhafte Einsatzfelder
- Predictive Maintenance: Ein Agent liest Sensordaten, korreliert mit Wartungshistorien, schlägt einen Eingriffszeitpunkt vor. Lippert nutzt nach Angabe von Databricks agent-gestützte Analytik, um Wartungsbedarf in Fertigung und Logistik zu antizipieren.
- Wettbewerbsmonitoring: Ein Agent recherchiert wöchentlich definierte Wettbewerber, analysiert Preisseiten, erstellt einen Vergleichsreport. Klassischer Fall hoher Pfadvielfalt — jede Woche andere Auffälligkeiten.
- Dokumenten-Review: Ein Orchestrator-Agent verteilt die Prüfung eines Vertrags oder Berichts auf spezialisierte Worker. Ein Worker extrahiert relevante Klauseln, einer prüft gegen interne Vorgaben, einer fasst zusammen. Hier zerfällt die Aufgabe in spezialisierte Subaufgaben. Ein typischer Kandidat für ein Multi-Agent-System.
Wann KI-Agenten in der Realität scheitern
Gartner prognostiziert, dass bis Ende 2027 über 40 Prozent der agentischen KI-Projekte abgebrochen werde. Vornehmlich wegen eskalierender Kosten, unklarem Geschäftswert oder unzureichender Risikokontrollen.
Die wiederkehrenden Scheiternsmuster lassen sich vorab erkennen:
- Context Rot: Der Agent zieht in langen Loops immer mehr Kontext mit; relevante Informationen verschwinden im Rauschen. Vorab-Indikator: Steigende Latenz und sinkende Trefferqualität bei zunehmender Loop-Länge in der Testphase.
- Quadratisches Token-Wachstum: Jeder neue Loop-Schritt verarbeitet den gesamten bisherigen Kontext. Dadurch wachsen Kosten und Latenz nicht linear. Vorab-Indikator: Token-Verbrauch pro Aufgabe in Test-Runs nicht mitgemessen.
- Fehlendes Checkpointing: Bricht ein Schritt ab, muss man von vorn beginnen. Vorab-Indikator: Architekturdiagramm zeigt keinen Persistenzlayer für Zwischenstände.
- Governance-Lücken: Agenten dürfen Aktionen ausführen, ohne dass Berechtigungen, Audit-Logs und Eskalationspfade definiert sind. Vorab-Indikator: Niemand kann benennen, was der Agent darf und was nicht — und wer haftet, wenn er es trotzdem tut.
Was der EU AI Act für KI-Agenten verlangt
Der EU AI Act trat am 1. August 2024 in Kraft und wird stufenweise anwendbar. Die letzte große Stufe, ursprünglich für den 2. August 2026 vorgesehen, betrifft die volle Durchsetzbarkeit der Anforderungen für Hochrisiko-KI-Systeme nach Anhang III. Eine politische Einigung im Mai 2026 (Digital-Omnibus-Paket) sieht eine Verschiebung um rund 16 Monate für Annex-III-Systeme vor; der formale Beschluss stand zum Redaktionsstand noch aus. Bußgelder bei Verstößen erreichen bis zu 35 Mio. € oder 7 Prozent des weltweiten Jahresumsatzes.
Hochrisiko nach Anhang III umfasst unter anderem KI-Systeme im Personalwesen (Bewerberauswahl, Beurteilungen), in der Kreditwürdigkeitsprüfung und in kritischer Infrastruktur. Ein KI-Agent, der etwa eingehende Bewerbungen vorsortiert oder Kreditanträge vorprüft, fällt damit in die Hochrisiko-Kategorie — unabhängig davon, ob die Entscheidung am Ende ein Mensch trifft.
Für solche Systeme gelten konkrete Pflichten, die in der Agentenarchitektur vorgesehen sein müssen:
- Risikomanagementsystem: Dokumentierte Identifikation, Bewertung und Minderung von Risiken über den gesamten Lebenszyklus.
- Daten-Governance: Anforderungen an Trainings- und Eingabedaten (Relevanz, Repräsentativität, Fehlerfreiheit, Vollständigkeit).
- Technische Dokumentation: Vollständige Beschreibung von Design, Funktionsweise, Leistungskennzahlen, Einschränkungen und Verwendungszweck — vor Inverkehrbringen.
- Protokollierung: Automatische Aufzeichnung von Eingaben, Ausgaben und Entscheidungen. Für Agenten heißt das: Jeder Tool-Call, jeder Planungsschritt, jede Reflexion muss auditierbar sein.
Wer einen Agenten plant, der in eine Hochrisiko-Kategorie fallen kann, muss Logging, Konformitätsbewertung und Dokumentation von Anfang an als Architekturanforderung behandeln — nicht als nachträglichen Compliance-Layer.
FAQ
Kann ein Unternehmen KI-Agenten selbst entwickeln oder braucht es externe Hilfe?
Prototypen lassen sich mit Standardframeworks intern realisieren, wenn Datenzugriff und LLM-Infrastruktur vorhanden sind. Der produktive Betrieb — insbesondere mehrere koordinierte Agenten, Governance, Audit-Logging und Kostensteuerung — erfordert in der Regel Spezialwissen, das in den meisten Unternehmen noch nicht aufgebaut ist. Die hohen Abbruchraten betreffen vor allem Projekte, die den Sprung vom Prototyp in Produktion unterschätzen.
Wie viele Tokens verbraucht ein KI-Agent pro Aufgabe?
Einfache Tool-Calling-Agenten liegen bei 5.000–15.000 Tokens pro Aufgabe, komplexe Multi-Agent-Systeme bei 200.000 bis über 1.000.000. Im Vergleich zu einer einzelnen Chat-Interaktion ist das 5- bis 30-mal mehr. Token-Verbrauch pro Aufgabe sollte schon in der Testphase gemessen werden, nicht erst in Produktion.
Ist ein KI-Agent dasselbe wie Agentic AI?
Nein. Der KI-Agent ist das konkrete Softwaresystem; Agentic AI bezeichnet die zugrundeliegende Eigenschaft, autonom und zielgerichtet zu handeln. Ein Agent ist ein Artefakt, Agentic AI ein Eigenschaftsbegriff — Anbieter, die beides synonym verwenden, sind ein Indikator für unscharfe Begriffsführung.
Ab wann ist ein KI-Agent ein Hochrisiko-System im Sinne des EU AI Act?
Sobald er in einem der in Anhang III genannten Anwendungsbereiche eingesetzt wird — darunter Personalentscheidungen, Kreditwürdigkeitsprüfung und kritische Infrastruktur. Die volle Durchsetzbarkeit der Hochrisiko-Anforderungen war für den 2. August 2026 vorgesehen; eine politische Einigung im Mai 2026 sieht eine Verschiebung um rund 16 Monate vor, der formale Beschluss steht noch aus. Die Einstufung hängt am Einsatzzweck, nicht an der technischen Komplexität des Agenten.